本文共 1686 字,大约阅读时间需要 5 分钟。
一.Cascade CNN的框架结构
1.Cascade CNN的整体框架

级联结构中有6个CNN,3个CNN用于人脸非人脸二分类,另外3个CNN是边界校正网络,用于人脸区域的边框校正。给定一幅图像,12-net密集扫描整幅图片,拒绝90%以上的窗口。剩余的窗口输入到12-calibration-net中调整大小和位置,以接近真实目标。接着输入到NMS中,消除高度重叠窗口。
2.12-net、24-net、48-net的网络框架结构

这三个网络的结构大致相同,不同之处在于其读入的图片分辨率和网络的复杂度是逐级递增的。前面的简单网络拒绝了绝大部分非人脸区域,将难以分辨的交由下一级更复杂的网路以获得更准确的结果。
想要在CNN结构下实现V-J瀑布级联结构,就要保证瀑布的前端足够简单并有较高的召回率且能够拒绝绝大部分非人脸区域,将图片缩放可以满足需求,比例为12/F,24/F,48/F,F为检测人脸的最小尺寸,这样对于一张800 * 600的图片,检测尺寸为40 * 40的人脸,窗口移动步伐为4个像素,那么会产生((800 * 12/40 - 12)/ 4 + 1) * ((600 * 12/40 - 12) / 4 + 1) = 2494个窗口。这样不仅使得窗口数量变少而且窗口的缩放也使得前期的CNN结构更加简单,实现了级联的思想。
另外在24-net和48-net的全连接层还会连接该图像缩放后在前一层网络的全连接输出,这么做的目的是为了检测更小的人脸,可以较明显的提高识别率。
3.12-calibration-net、24-calibration-net、48-calibration-net的网络框架结构

这三个网络用于校正人脸检测框的边界,往往得分最高的边界框并非最佳结果,经过校准后能更好的定位人脸。其校正原理非常简单:对原图做45次变换,然后每个变换后的边界框都有一个得分,对于得分高于某个设定的阈值时,将其加进原边界,最后取平均,就是最佳边界框。
45次变换如下所示:
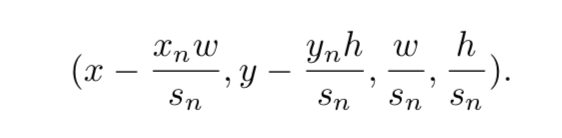
其中Sn是尺寸的缩放比例,Xn和Yn是坐标移动比例,取值分别如下所示:

二.Cascade CNN人脸校验模块原理
该网络用于窗口校正,使用三个偏移变量:Xn:水平平移量,Yn:垂直平移量,Sn:宽高比缩放。候选框口(x,y,w,h)中,(x,y)表示左上角点坐标,(w,h)表示宽和高。
我们要将窗口的控制坐标调整为:

在这项工作中,我们有N = 5 * 3 * 3 = 45种模式。偏移向量三个参数包含以下值:
S n : ( 0.83 , 0.91 , 1.0 , 1.10 , 1.21 ) Sn:(0.83,0.91,1.0,1.10,1.21) Sn:(0.83,0.91,1.0,1.10,1.21)
X n : ( − 0.17 , 0 , 0.17 ) Xn:(-0.17,0,0.17) Xn:(−0.17,0,0.17)
Y n : ( − 0.17 , 0 , 0.17 ) Yn:(-0.17,0,0.17) Yn:(−0.17,0,0.17)
同时对偏移向量三个参数进行校正:

三.训练样本的准备
人脸样本
非人脸样本四.级联的优势
- 最初阶段的网络可以比较简单,判别阈值可以设得宽松一点,这样就可以在保持较高召回率的同时排除掉大量的人非人脸窗口。
- 最后阶段网络为了保证足够的性能,因此一般设计的比较复杂,但由于只需要处理前面剩下的窗口,因此可以保证足够的效率。
- 级联的思想可以帮助我们去组合利用性能较差的分类器,同时又可以获得一定的效率保证。
五.Cascade CNN的主要贡献
- Cascade CNN是一种非常快速的人脸检测算法。对传统的VGA图像检测在CPU上可以达到14FPS,在GPU上可以达到100FPS。
- 在FDDB上达到了当年最好的分数。
- 我们先用CNN网络在低分辨率下对输入图像进行评估,达到快速剔除非人脸区域的目的,并在高分辨率下仔细处理具有挑战性的区域,以达到准确检测的目的。
- 设计了边界校正网络用于更好的定位人脸位置。
转载地址:http://lbbiz.baihongyu.com/